

Enregistrement et lecture de fichiers de données
Assurez-vous toujours de vérifier trois fois si vos données ont été correctement enregistrées avant de lancer votre expérience !
Utiliser l'élément logger
OpenSesame ne va pas enregistrer vos données automatiquement. Au lieu de cela, vous devez insérer un élément logger, généralement à la fin de votre séquence de test.
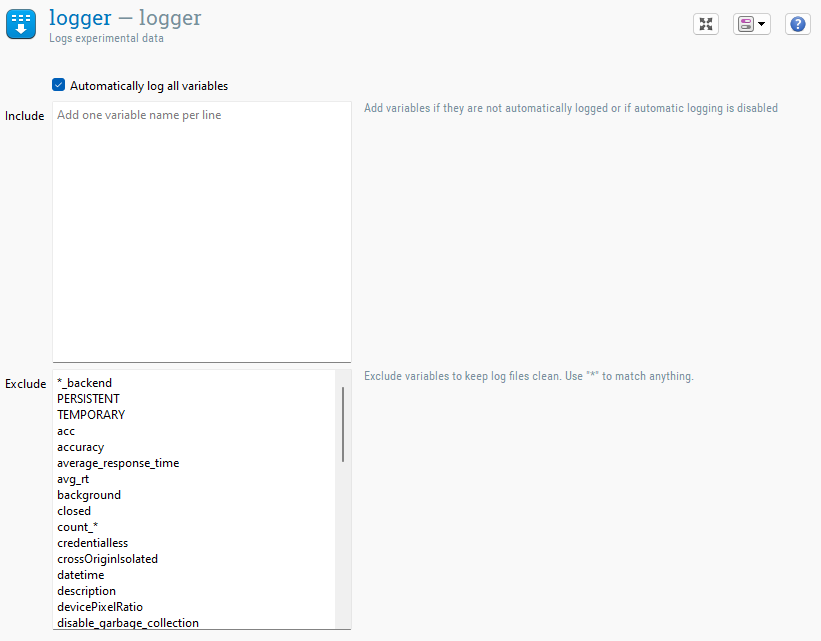
Figure 1. L'élément logger.
La manière la plus simple d'utiliser logger est de laisser l'option 'Automatically log all variables' activée. De cette façon, toutes les variables que OpenSesame connaît sont écrites dans le fichier de log, à l'exception de celles qui sont explicitement exclues (voir ci-dessous).
Vous pouvez explicitement inclure les variables que vous souhaitez enregistrer. La raison principale de le faire est lorsque vous constatez que certaines variables manquent (parce qu'OpenSesame ne les a pas automatiquement détectées), ou si vous avez désactivé l'option 'Automatically log all variables'.
Vous pouvez également exclure explicitement certaines variables du fichier de log. La raison principale de le faire est de garder les fichiers de log propres en excluant les variables qui ne sont généralement pas utiles.
En général, vous ne devriez créer qu'un seul élément logger et réutiliser ce logger à différents endroits de votre expérience si nécessaire (c'est-à-dire utiliser des copies liées du même élément logger). Si vous créez plusieurs loggers (au lieu d'utiliser un seul logger plusieurs fois), ils écriront tous dans le même fichier de log, et le résultat sera un désordre !
Utiliser le script inline Python
Vous pouvez écrire dans le fichier de log en utilisant l'objet log :
log.write('Ceci sera écrit dans le fichier de log !')
Pour plus d'informations, voir :
Vous ne devriez généralement pas écrire directement dans le fichier de log et utiliser un élément logger en même temps ; cela entraînerait des fichiers de log désordonnés.
Format des fichiers de données
Si vous avez utilisé l'élément logger standard, les fichiers de données ont le format suivant (simplement du csv standard) :
- texte brut
- séparés par des virgules
- entre guillemets doubles (les guillemets littéraux sont échappés avec des barres obliques inverses)
- fin de ligne de style Unix
- codés en UTF-8
- noms des colonnes sur la première ligne
Quelles variables sont enregistrées ?
Par défaut, les variables définies dans l'interface utilisateur, telles que les colonnes dans une table de loop ou les variables de réponse, sont toujours enregistrées.
Par défaut, les variables définies dans un inline_script ou inline_javascript sont enregistrées si ce sont des nombres (int et float), des chaînes (str et bytes), et des valeurs None. Cela évite que les fichiers de log deviennent déraisonnablement grands à cause de l'enregistrement de longues listes et d'autres grandes valeurs. (Depuis OpenSesame 4.0, il n'est plus nécessaire d'utiliser l'objet var (Python) ou vars (JavaScript).)
Si vous souhaitez enregistrer explicitement une variable qui n'est pas enregistrée par défaut, vous pouvez utiliser le champ 'Include' dans l'élément logger.
Lire et traiter les fichiers de données
En Python avec pandas ou DataMatrix
En Python, vous pouvez utiliser pandas pour lire des fichiers csv.
import pandas
df = pandas.read_csv('subject-1.csv')
print(df)
Ou DataMatrix :
from datamatrix import io
dm = io.readtxt('subject-1.csv')
print(dm)
En R
En R, vous pouvez simplement utiliser la fonction read.csv() pour lire un seul fichier de données.
df = read.csv('subject-1.csv', encoding = 'UTF-8')
head(df)
De plus, vous pouvez utiliser la fonction read_opensesame() du package readbulk pour lire et fusionner facilement plusieurs fichiers de données en un grand cadre de données. Le package est disponible sur CRAN et peut être installé via install.packages('readbulk').
# Lire et fusionner tous les fichiers de données stockés dans le dossier 'raw_data'
library(readbulk)
df = read_opensesame('raw_data')
Dans JASP
JASP, un logiciel de statistiques open-source, ouvre directement les fichiers csv.
Dans LibreOffice Calc
Si vous ouvrez un fichier csv dans LibreOffice Calc, vous devez indiquer le format exact des données, comme indiqué dans Figure 2. (Les paramètres par défaut sont souvent corrects.)
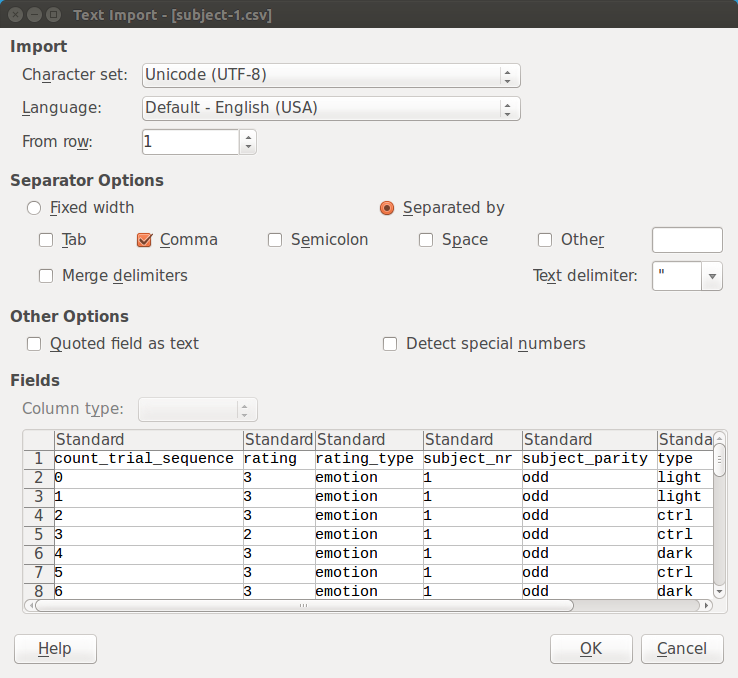
Figure 2.
Dans Microsoft Excel
Dans Microsoft Excel, vous devez utiliser l'Assistant Importation de texte.
Fusionner plusieurs fichiers de données en un seul gros fichier
Pour certains besoins, tels que l'utilisation de tableaux croisés dynamiques, il peut être pratique de fusionner tous les fichiers de données en un seul gros fichier. Avec Python DataMatrix, vous pouvez le faire avec le script suivant :
import os
from datamatrix import DataMatrix, io, operations as ops
# Changez ceci pour le dossier qui contient les fichiers .csv
SRC_FOLDER = 'student_data'
# Changez ceci pour une liste de noms de colonnes que vous souhaitez conserver
COLUMNS_TO_KEEP = [
'RT_search',
'load',
'memory_resp'
]
dm = DataMatrix()
for basename in os.listdir(SRC_FOLDER):
path = os.path.join(SRC_FOLDER, basename)
print('Lecture de {}'.format(path))
dm <<= ops.keep_only(io.readtxt(path), *COLUMNS_TO_KEEP)
io.writetxt(dm, 'merged-data.csv')
Enregistrement dans OSWeb
Lorsque vous exécutez une expérience dans un navigateur avec OSWeb, l'enregistrement des données fonctionne différemment de lorsque vous exécutez une expérience sur le bureau.
Spécifiquement, lorsque vous lancez une expérience OSWeb directement depuis OpenSesame, le fichier de log est téléchargé à la fin de l'expérience. Ce fichier de log est au format .json. Lorsque vous lancez une expérience OSWeb depuis JATOS, il n'y a pas de fichier de log en tant que tel, mais toutes les données sont envoyées à JATOS, d'où elles peuvent être téléchargées.
Voir aussi :