


Protokollierung und Lesen von Datendateien
Überprüfen Sie immer dreifach, ob Ihre Daten korrekt protokolliert wurden, bevor Sie Ihr Experiment durchführen!
Verwenden des Logger-Elements
OpenSesame protokolliert Ihre Daten nicht automatisch. Stattdessen müssen Sie ein logger-Element einfügen, in der Regel am Ende Ihrer Versuchssequenz.
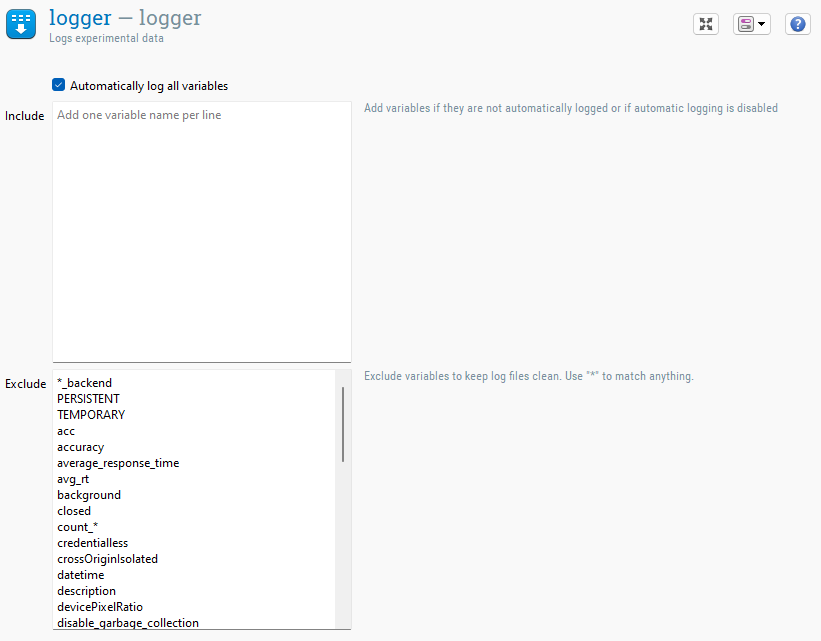
Figure 1. Das logger-Element.
Die einfachste Art, den logger zu verwenden, ist, die Option 'Automatisch alle Variablen protokollieren' aktiviert zu lassen. Auf diese Weise werden alle Variablen, die OpenSesame kennt, in die Protokolldatei geschrieben, außer denen, die explizit ausgeschlossen sind (siehe unten).
Sie können ausdrücklich einschließen, welche Variablen Sie protokollieren möchten. Der Hauptgrund dafür ist, wenn Sie feststellen, dass einige Variablen fehlen (weil OpenSesame sie nicht automatisch erkannt hat), oder wenn Sie die Option 'Automatisch alle Variablen protokollieren' deaktiviert haben.
Sie können auch bestimmte Variablen explizit von der Protokolldatei ausschließen. Der Hauptgrund hierfür ist, die Protokolldateien sauber zu halten, indem Variablen ausgeschlossen werden, die allgemein nicht nützlich sind.
Im Allgemeinen sollten Sie nur ein Logger-Element erstellen und diesen logger bei Bedarf an verschiedenen Stellen in Ihrem Experiment wiederverwenden (d.h. verknüpfte Kopien desselben logger-Elements verwenden). Wenn Sie mehrere logger erstellen (anstatt einen einzigen logger mehrmals zu verwenden), werden sie alle in die gleiche Protokolldatei schreiben, und das Ergebnis wird ein Durcheinander sein!
Verwenden von Python Inline-Skript
Sie können mit dem log-Objekt in die Protokolldatei schreiben:
log.write('Dies wird in die Protokolldatei geschrieben!')
Weitere Informationen finden Sie unter:
Sie sollten im Allgemeinen nicht direkt in die Protokolldatei schreiben und gleichzeitig ein logger-Element verwenden; dies würde in unordentlichen Protokolldateien resultieren.
Format der Datendateien
Wenn Sie das Standard-logger-Element verwendet haben, sind die Datendateien im folgenden Format (einfach standardmäßiges csv):
- Klartext
- kommagetrennt
- doppelte Anführungszeichen (wörtliche doppelte Anführungszeichen werden mit Rückwärtsschrägstrichen maskiert)
- Unix-Stil Zeilenenden
- UTF-8-kodiert
- Spaltennamen in der ersten Zeile
Welche Variablen werden protokolliert?
Standardmäßig werden Variablen, die in der Benutzeroberfläche definiert sind, wie Spalten in einer loop-Tabelle oder Antwortvariablen, immer protokolliert.
Standardmäßig werden Variablen, die in einem inline_script oder inline_javascript definiert sind, protokolliert, wenn es sich um Zahlen (int und float), Zeichenketten (str und bytes), und None-Werte handelt. Dies soll vermeiden, dass Protokolldateien unvernünftig groß werden, indem lange Listen und andere große Werte protokolliert werden. (Ab OpenSesame 4.0 ist es nicht mehr notwendig, das var (Python) oder vars (JavaScript) Objekt zu verwenden.)
Wenn Sie eine Variable, die nicht standardmäßig protokolliert wird, explizit protokollieren möchten, können Sie das Feld 'Einschließen' im logger-Element verwenden.
Lesen und Verarbeiten von Datendateien
In Python mit pandas oder DataMatrix
In Python können Sie pandas verwenden, um csv-Dateien zu lesen.
import pandas
df = pandas.read_csv('subject-1.csv')
print(df)
Oder DataMatrix:
from datamatrix import io
dm = io.readtxt('subject-1.csv')
print(dm)
In R
In R können Sie einfach die Funktion read.csv() verwenden, um eine einzelne Datendatei zu lesen.
df = read.csv('subject-1.csv', encoding = 'UTF-8')
head(df)
Darüber hinaus können Sie die Funktion read_opensesame() aus dem readbulk Paket verwenden, um einfach mehrere Datendateien in einen großen Datenrahmen zu lesen und zusammenzufügen. Das Paket ist auf CRAN verfügbar und kann über install.packages('readbulk') installiert werden.
# Lesen und Zusammenfügen aller Datendateien, die im Ordner 'raw_data' gespeichert sind
library(readbulk)
df = read_opensesame('raw_data')
In JASP
JASP, ein Open-Source-Statistikpaket, öffnet csv-Dateien direkt.
In LibreOffice Calc
Wenn Sie eine CSV-Datei in LibreOffice Calc öffnen, müssen Sie das genaue Datenformat angeben, wie in Figure 2 dargestellt. (Die Standardeinstellungen sind oft korrekt.)
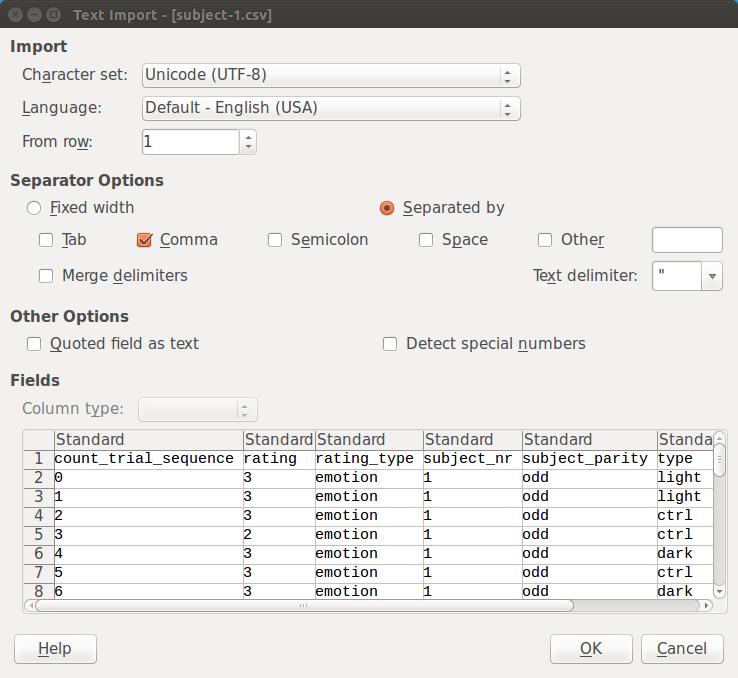
Figure 2.
In Microsoft Excel
In Microsoft Excel müssen Sie den Textimport-Assistenten verwenden.
Zusammenführen mehrerer Datendateien in eine große Datei
Für bestimmte Zwecke, wie die Verwendung von Pivot-Tabellen, kann es praktisch sein, alle Datendateien in eine große Datei zusammenzuführen. Mit Python DataMatrix können Sie dies mit dem folgenden Skript tun:
import os
from datamatrix import DataMatrix, io, operations as ops
# Ändern Sie dies in den Ordner, der die .csv-Dateien enthält
SRC_FOLDER = 'student_data'
# Ändern Sie dies in eine Liste von Spaltennamen, die Sie behalten möchten
COLUMNS_TO_KEEP = [
'RT_search',
'load',
'memory_resp'
]
dm = DataMatrix()
for basename in os.listdir(SRC_FOLDER):
path = os.path.join(SRC_FOLDER, basename)
print('Lese {}'.format(path))
dm <<= ops.keep_only(io.readtxt(path), *COLUMNS_TO_KEEP)
io.writetxt(dm, 'merged-data.csv')
Logging in OSWeb
Wenn Sie ein Experiment in einem Browser mit OSWeb ausführen, funktioniert das Logging anders als wenn Sie ein Experiment auf dem Desktop ausführen.
Speziell, wenn Sie ein OSWeb-Experiment direkt aus OpenSesame heraus starten, wird die Protokolldatei am Ende des Experiments heruntergeladen. Diese Protokolldatei ist im .json-Format. Wenn Sie ein OSWeb-Experiment von JATOS aus starten, gibt es keine eigentliche Protokolldatei, sondern alle Daten werden an JATOS gesendet, von wo aus sie heruntergeladen werden können.
Siehe auch: