


Visuelle Welt
- Über dieses Tutorial
- Über das Experiment
- Das Tutorial
- Schritt 1: Laden Sie OpenSesame herunter und starten Sie es
- Schritt 2: Erstellen Sie die Hauptstruktur des Experiments
- Schritt 3: Dateien in den Datei-Pool importieren
- Schritt 4: Experimentelle Variablen im block_loop definieren
- Schritt 5: Erweiterte Loop-Operationen anwenden
- Schritt 6: Erstellen Sie die Versuchssequenz
- Schritt 7: Definiere die visuellen Stimuli
- Schritt 8: Definieren Sie den Ton
- Schritt 9: Grundlegendes Eye-Tracking hinzufügen
- Schritt 10: Anweisungen und Abschiedsbildschirm definieren
- Schritt 11: Führen Sie das Experiment aus!
- Zusatzaufgaben
- Lade das Experiment herunter
- Literaturangaben
Über dieses Tutorial
Dieses Tutorial setzt grundlegende Kenntnisse in OpenSesame und in einigen Teilen Python voraus. Wenn Sie mit OpenSesame oder Python noch nicht vertraut sind, empfehle ich Ihnen, zunächst das Anfänger- und Fortgeschrittenen-Tutorial durchzuarbeiten, bevor Sie mit diesem Tutorial fortfahren:
- https://osdoc.cogsci.nl/4.0/de/tutorials/beginner
- https://osdoc.cogsci.nl/4.0/de/tutorials/intermediate
In diesem Tutorial lernen Sie Folgendes:
- Eye-Tracking mit PyGaze
- Parallele Aufgaben mit
coroutines - Erweiterte
loop-Operationen verwenden
Über das Experiment
In diesem Tutorial werden wir ein Visual-World-Paradigma implementieren, das von Cooper (1974; für einen Überblick siehe auch Huettig, Rommers und Meyer, 2011) eingeführt wurde. In diesem Paradigma hören die Teilnehmer einen gesprochenen Satz, während sie sich eine Anzeige mit mehreren Objekten ansehen. Wir werden vier separate Objekte verwenden, die in den vier Quadranten der Anzeige dargestellt werden (Figure 1).
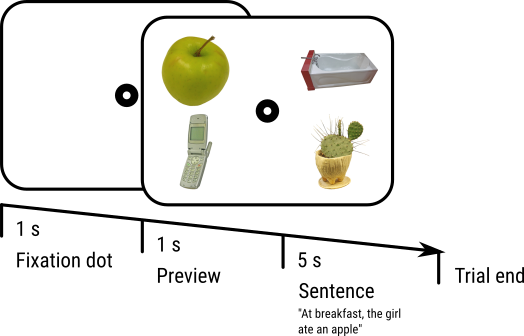
Figure 1. Ein Schema unserer Versuchsreihenfolge. Dies ist ein Beispiel für eine Vollständige-Übereinstimmung, da das Zielobjekt (der Apfel) im gesprochenen Satz direkt erwähnt wird. Die verwendeten Reize stammen aus den BOSS Reizen (Brodier et al., 2010).
Der gesprochene Satz bezieht sich auf eines oder mehrere der Objekte. Zum Beispiel kann ein Apfel (das Zielobjekt) gezeigt werden, während der gesprochene Satz "zum Frühstück aß das Mädchen einen Apfel" abgespielt wird. In diesem Fall stimmt das Ziel vollständig mit dem Satz überein. Der Satz kann sich auch indirekt auf ein gezeigtes Objekt beziehen. Zum Beispiel kann ein Apfel (wieder das Zielobjekt) gezeigt werden, während der gesprochene Satz "zum Frühstück aß das Mädchen eine Banane" abgespielt wird. In diesem Fall stimmt das Ziel semantisch mit dem Satz überein, da eine Banane und ein Apfel beide Früchte sind, die ein Mädchen zum Frühstück essen kann.
Während des Experiments wird die Augenposition erfasst und der Anteil der Fixierungen auf Ziel- und Nichtzielobjekte wird über die Zeit gemessen. Die typische Erkenntnis ist dann, dass die Augen auf Zielobjekte gerichtet sind, d.h. die Teilnehmer sehen sich hauptsächlich Objekte an, die direkt oder indirekt in dem gesprochenen Satz erwähnt werden. Je direkter die Referenz ist, desto stärker ist dieser Effekt.
Lassen Sie uns dies nun formeller gestalten. Unser Experiment hat folgendes Design:
- Ein Faktor (Zielübereinstimmung) mit zwei Ebenen (Vollständig oder Semantisch), innerhalb der Probanden variabel. In der Vollständigen-Übereinstimmungsbedingung wird das Zielobjekt direkt im Satz erwähnt. In der Semantischen-Übereinstimmungsbedingung ist das Zielobjekt semantisch mit einem im Satz erwähnten Objekt verwandt.
- Wir haben 16 gesprochene Sätze und sechzehn Zielobjekte. Jeder Satz und jedes Zielobjekt wird zweimal gezeigt: einmal in der Vollständigen-Übereinstimmungsbedingung und einmal in der Semantischen-Übereinstimmungsbedingung.
- Wir haben 16 × 3 = 48 ablenkende Objekte, von denen jedes (wie die Ziele) zweimal gezeigt wird.
- Jeder Versuch beginnt mit einem Fixierungspunkt für 1 s, gefolgt von der Präsentation der Reize, was 1 s später vom Start des gesprochenen Satzes gefolgt wird. Der Versuch endet 5 s später.
Das Tutorial
Schritt 1: Laden Sie OpenSesame herunter und starten Sie es
OpenSesame ist für Windows, Linux, Mac OS (experimentell) und Android (nur Runtime) verfügbar. Dieses Tutorial ist für OpenSesame 3.2.X Kafkaesque Koffka geschrieben. Um PyGaze verwenden zu können, sollten Sie die Python 2.7-Version herunterladen (die Standardversion). Sie können OpenSesame hier herunterladen:
(Wenn Sie OpenSesame zum ersten Mal starten, sehen Sie eine Willkommensseite. Schließen Sie diese Seite.) Wenn Sie OpenSesame starten, haben Sie die Möglichkeit, ein Template-Experiment auszuwählen und (falls vorhanden) eine Liste der zuletzt geöffneten Experimente zu sehen (siehe Figure 2). Klicken Sie auf "Standardvorlage", um mit einem fast leeren Experiment zu beginnen.
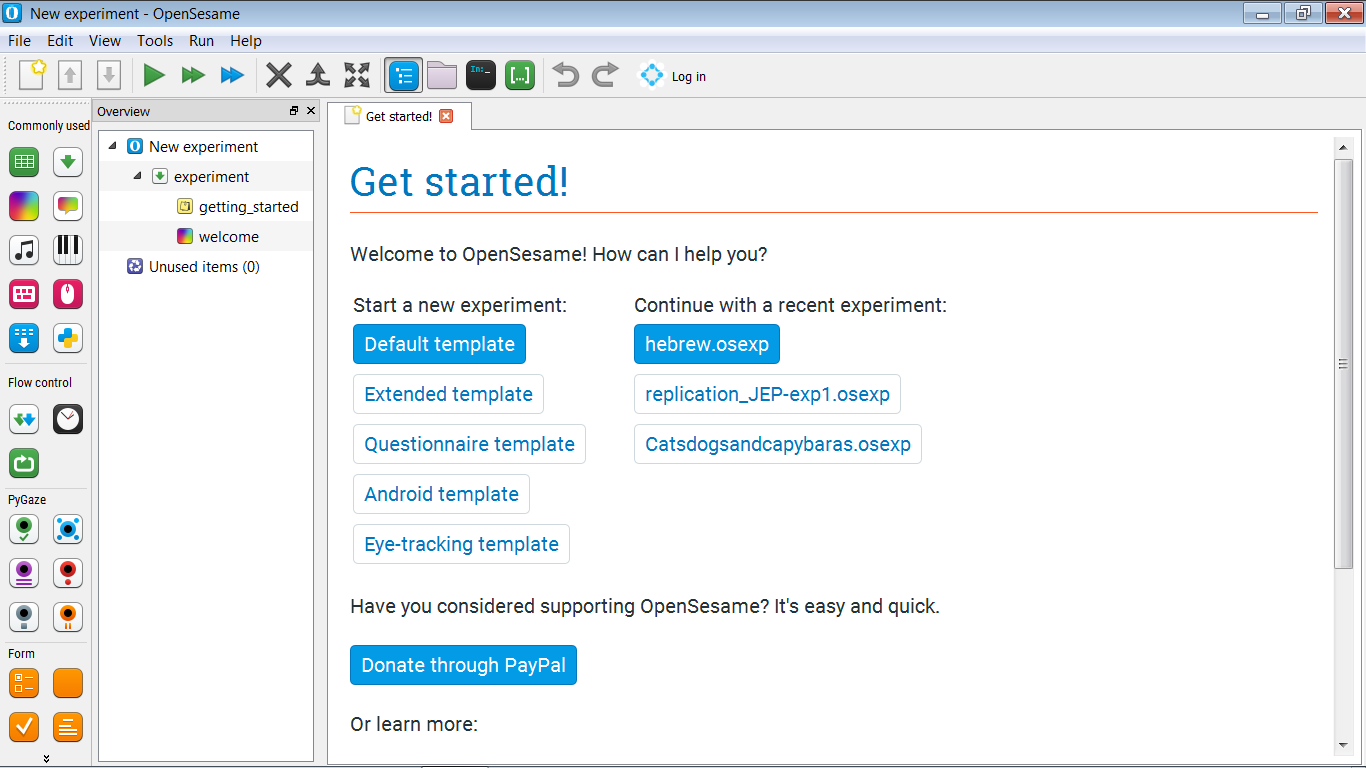
Figure 2. Das OpenSesame-Fenster beim Start.
Schritt 2: Erstellen Sie die Hauptstruktur des Experiments
Für den Moment erstellen Sie die folgende Hauptstruktur für Ihr Experiment (siehe auch Figure 3):
- Wir beginnen mit einem Anleitungsbildschirm. Dies wird ein
sketchpadsein. - Als nächstes führen wir einen Block von Versuchen durch. Dies wird eine einzelne
sequence, die einem einzelnen Versuch entspricht, innerhalb einer einzelnenloop, die einem Block von Versuchen entspricht. Sie können die Versuchssequenz vorerst leer lassen! - Schließlich enden wir mit einem Abschiedsbildschirm.
Wir müssen auch die Vordergrundfarbe des Experiments auf Schwarz und die Hintergrundfarbe auf Weiß ändern. Dies liegt daran, dass wir Bilder mit weißem Hintergrund verwenden werden und wir nicht möchten, dass diese Bilder auffallen!
Und vergessen Sie nicht, Ihrem Experiment einen sinnvollen Namen zu geben und es zu speichern!
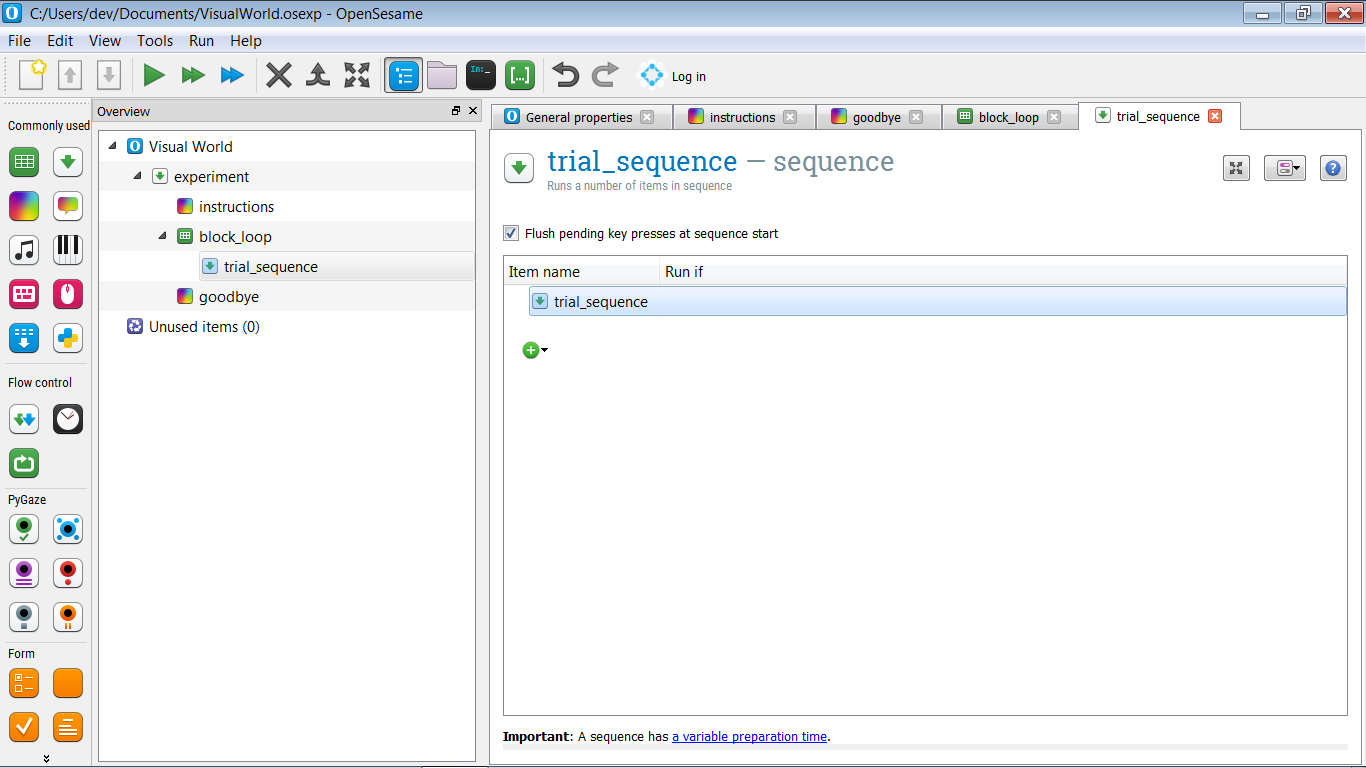
Figure 3. Die Hauptstruktur des Experiments.
Schritt 3: Dateien in den Datei-Pool importieren
Für dieses Experiment benötigen wir Reize: Tondateien für die gesprochenen Sätze und Bilddateien für die Objekte. Laden Sie diese über den folgenden Link herunter, extrahieren Sie die zip-Datei und legen Sie die Reize im Datei-Pool Ihres Experiments ab (siehe auch Figure 4).
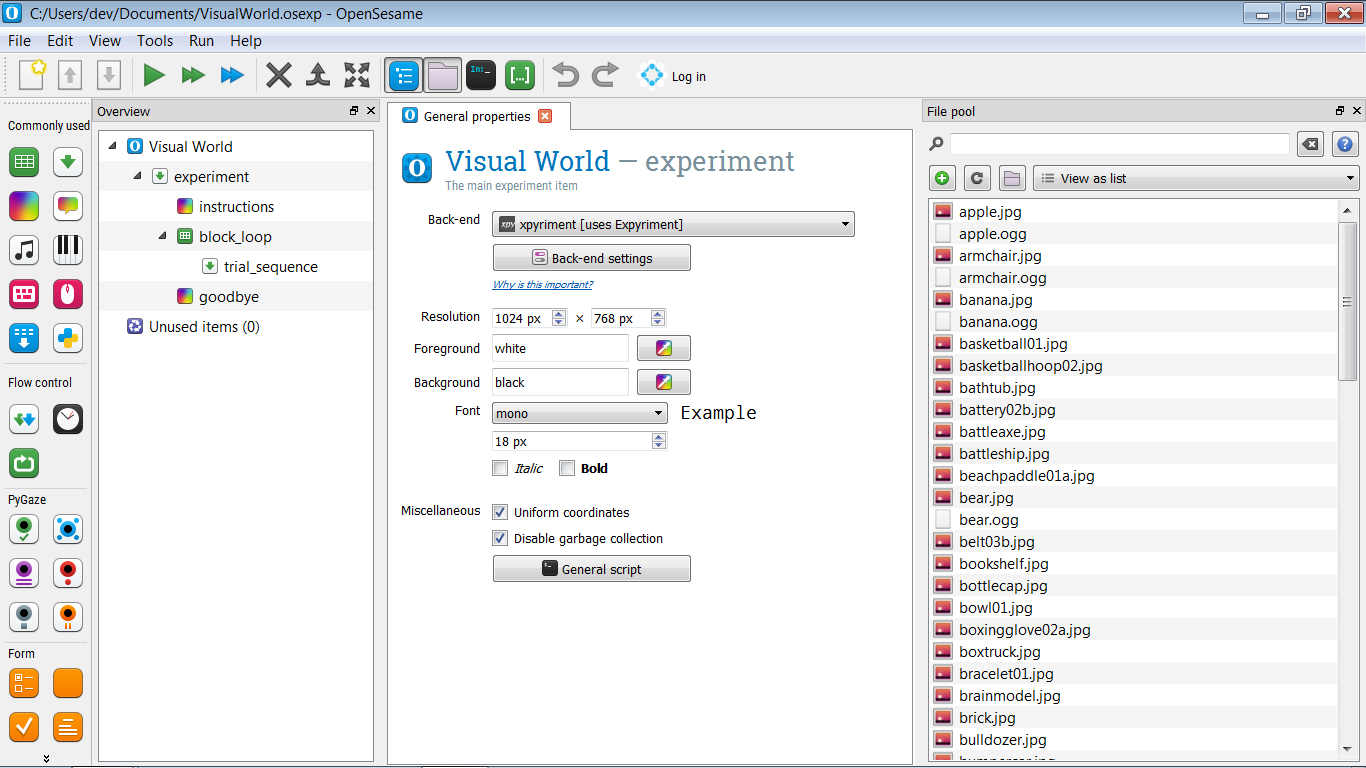
Figure 4. Der Datei-Pool Ihres Experiments, nachdem alle Reize hinzugefügt wurden.
Schritt 4: Experimentelle Variablen im block_loop definieren
Im block_loop definieren wir die experimentellen Variablen, indem wir sie in eine Tabelle eingeben, bei der jede Zeile einem Versuch und jede Spalte einer experimentellen Variable entspricht.
Zunächst definieren wir nur die Full Match-Bedingung, bei der das Zielobjekt direkt im gesprochenen Satz erwähnt wird. (Wir werden die Semantic Match-Bedingung im Rahmen der Zusatzaufgaben hinzufügen.)
Wir benötigen die folgenden Variablen. Fügen Sie zuerst einfach Spalten zur Loop-Tabelle hinzu, ohne den Zeilen einen Inhalt zu geben.
pic1— der Name des ersten Bildes (z.B. 'apple.jpg')pic2— der Name des zweiten Bildespic3— der Name des dritten Bildespic4— der Name des vierten Bildespos1— die Position des ersten Bildes (z.B. 'topleft')pos2— die Position des ersten Bildespos3— die Position des ersten Bildespos4— die Position des ersten Bildessound— der Name einer Tondatei, die einen gesprochenen Satz enthält (z.B. 'apple.ogg').
Das Zielobjekt wird immer pic1 entsprechen. Wir haben die folgenden Zielobjekte; das heißt, für die folgenden Objekte haben wir Tondateien, die sich auf sie beziehen. Kopieren Sie einfach die folgende Liste in die pic1-Spalte der Tabelle:
apple.jpg
armchair.jpg
banana.jpg
bear.jpg
card.jpg
cello.jpg
chicken.jpg
cookie.jpg
croissant.jpg
dice.jpg
egg.jpg
guitar.jpg
keyboard.jpg
mouse.jpg
sofa.jpg
wolf.jpg
Und machen Sie dasselbe für die Tondateien:
apple.ogg
armchair.ogg
banana.ogg
bear.ogg
card.ogg
cello.ogg
chicken.ogg
cookie.ogg
croissant.ogg
dice.ogg
egg.ogg
guitar.ogg
keyboard.ogg
mouse.ogg
sofa.ogg
wolf.ogg
Die restlichen Bilder sind Ablenker. Kopieren Sie die folgende Liste in die Spalten pic2, pic3 und pic4, sodass jede Spalte genau 16 Zeilen hat. (Wenn Sie die Tabelle versehentlich länger als 16 Zeilen machen, wählen Sie einfach die überflüssigen Zeilen aus, klicken Sie mit der rechten Maustaste und löschen Sie sie.)
basketball01.jpg
basketballhoop02.jpg
badewanne.jpg
battery02b.jpg
kampfaxt.jpg
schlachtschiff.jpg
beachpaddle01a.jpg
gurt03b.jpg
bücherregal.jpg
flaschenkappe.jpg
schüssel01.jpg
boxhandschuh02a.jpg
kastenwagen.jpg
armband01.jpg
gehirnmodell.jpg
ziegelstein.jpg
raupe.jpg
autoscooter.jpg
büste.jpg
knopf01.jpg
kaktus.jpg
rechner01.jpg
kalender.jpg
kamera01b.jpg
cd.jpg
deckenventilator02.jpg
handy.jpg
fäustling04.jpg
denkmal.jpg
mond.jpg
motorboot02.jpg
motorölbottle03b.jpg
mrpotatohead.jpg
nagelzwicker03b.jpg
spitznasezange03a.jpg
nachttisch.jpg
nintendods.jpg
noparkingsign.jpg
ofen.jpg
schnuller02a.jpg
farbdose01.jpg
hosen.jpg
papierflugzeug.jpg
papierclip02.jpg
parkbrunnen.jpg
terrassenregenschirm.jpg
bleistiftspitzer03b.jpg
pfeffermühle01a.jpg
Jetzt müssen wir die Positionen festlegen. Setzen Sie einfach:
pos1auf 'obenlinks'pos2auf 'obenrechts'pos3auf 'untenlinks'pos4auf 'untenrechts'
Ihre Loop-Tabelle sollte jetzt wie Figure 5 aussehen.
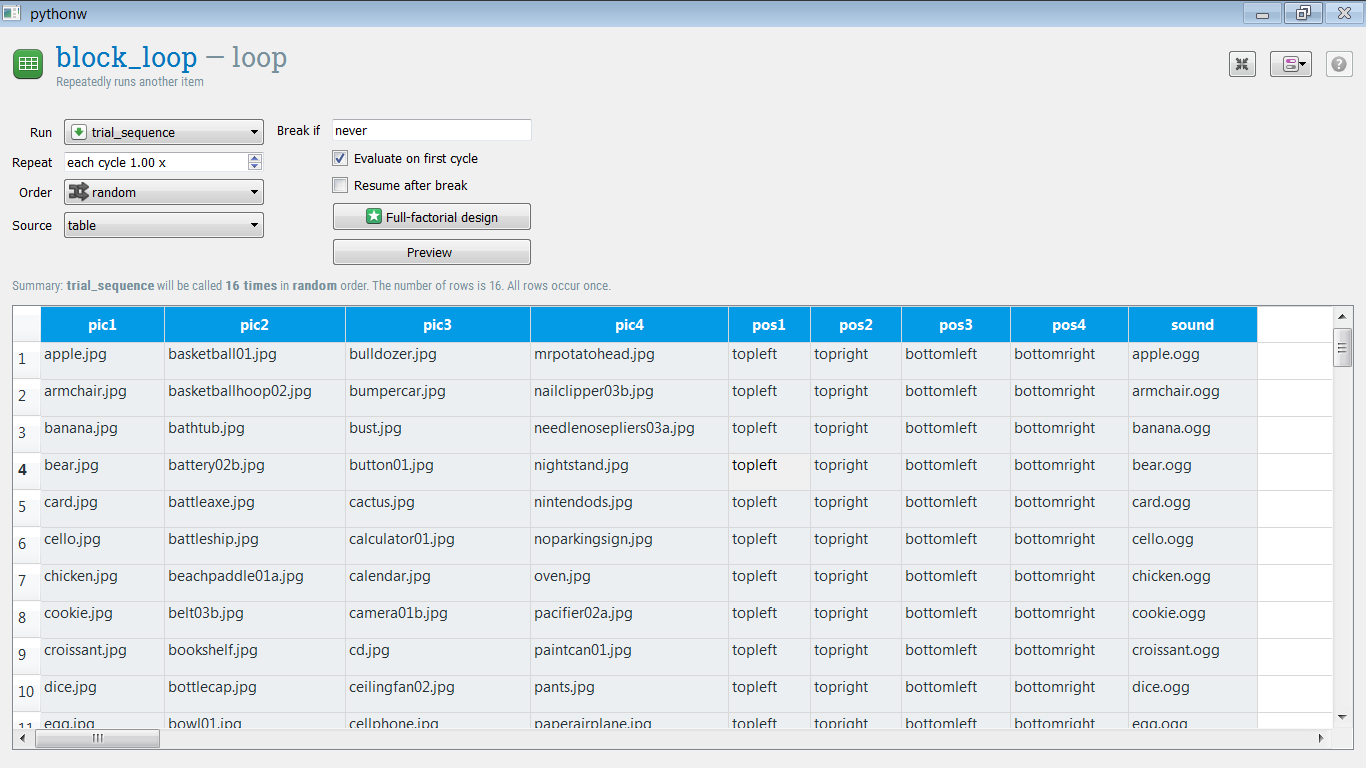
Figure 5. Die loop-Tabelle, nachdem alle experimentellen Variablen definiert wurden.
Schritt 5: Erweiterte Loop-Operationen anwenden
Obwohl Sie nun alle experimentellen Variablen definiert haben, ist die loop-Tabelle noch nicht fertig! Schauen wir, was nicht stimmt:
Positionen
pos1 ist immer oben links, d.h. pic1 (das Zielobjekt) wird immer oben links auf dem Bildschirm angezeigt! (Unter der Annahme, dass wir unsere Versuchssequenz so implementieren, dass diese Positionen auf diese Weise verwendet werden.) Und dasselbe gilt für pos2, pos3 und pos4.
Dies kann behoben werden, indem die pos[x] Spalten horizontal gemischt werden. Das heißt, für jede Zeile tauschen wir zufällig die Werte dieser Zeilen, so dass aus diesem:
pos1 pos2 pos3 pos4
obenlinks obenrechts untenlinks untenrechts
obenlinks obenrechts untenlinks untenrechts
…
(Sagen wir) das hier wird:
pos1 pos2 pos3 pos4
untenlinks obenlinks obenrechts untenrechts
obenrechts untenrechts obenrechts untenlinks
…
Um dies zu tun, sehen Sie sich das Skript von block_loop an und fügen Sie die folgende Codezeile am Ende des Skripts ein:
shuffle_horiz pos1 pos2 pos3 pos4
Klicken Sie auf 'Anwenden und schließen'. Wenn Sie nun auf "Vorschau" klicken, erhalten Sie eine Vorschau auf das, was Ihre Loop-Tabelle aussehen könnte, wenn das Experiment tatsächlich durchgeführt würde. Und Sie werden sehen, dass die pos[x]-Spalten horizontal gemischt sind, was bedeutet, dass die Bilder an zufälligen Positionen angezeigt werden!
Ablenkbilder
Die Ablenkbilder sind immer mit demselben Zielobjekt verknüpft. Zum Beispiel tritt "basketball01.jpg" immer zusammen mit dem Ziel "apple.jpg" auf. Aber das ist nicht das, was wir wollen! Vielmehr möchten wir, dass die Zuordnung zwischen Ablenkern und Zielobjekten zufällig ist und für alle Teilnehmer unterschiedlich ist. (Es sei denn, durch Zufall tritt eine identische Zuordnung für zwei Teilnehmer auf.)
Dies kann behoben werden, indem die pic2, pic3 und pic4 Spalten vertikal gemischt werden. D. h. die Reihenfolge jeder dieser Spalten sollte unabhängig voneinander gemischt werden. Um dies zu tun, sehen Sie sich das Skript erneut an und fügen Sie die folgenden Zeilen am Ende des Skripts ein:
shuffle pic2
shuffle pic3
shuffle pic4
Klicken Sie auf 'Anwenden und schließen'. Wenn Sie nun auf 'Vorschau' klicken, sehen Sie, dass die loop-Tabelle ordnungsgemäß randomisiert ist!
Weitere Informationen zu erweiterten Loop-Operationen finden Sie unter:
Frage
An diesem Punkt fragen Sie sich vielleicht, warum wir nicht auch die pic2, pic3 und pic4 Spalten horizontal mischen müssen. Aber das müssen wir nicht! Wissen Sie auch, warum nicht?
Schritt 6: Erstellen Sie die Versuchssequenz
Wie in Figure 1 gezeigt, ist unsere Versuchssequenz einfach und besteht aus:
- zentralem Fixationspunkt (ein
sketchpad) - Nach 1000 ms: Stimulusanzeige (ein weiteres
sketchpad) - Nach 1000 ms: Starten der Tonwiedergabe (ein
sampler) während die Stimulusanzeige auf dem Bildschirm bleibt - Nach 5000 ms: Versuchsende
Bisher ist die Versuchssequenz also rein sequenziell, und wir könnten sie nur mit einer sequence implementieren, wie wir es in anderen Tutorials getan haben. In einer der Extra-Aufgaben möchten wir jedoch die Augenposition während der Versuchssequenz analysieren. Mit anderen Worten, später wollen wir zwei Dinge parallel tun, und deshalb benötigen wir ein coroutines-Element. (Auch wenn wir jetzt noch nichts tun, was das erfordert.)
Wir möchten also folgende Struktur haben:
- trial_sequence sollte ein
coroutines-Element enthalten (nennen wir es trial_coroutines), gefolgt von einemlogger-Element. - trial_coroutines sollte eine Dauer von 7000 ms haben und drei Elemente enthalten:
- Ein
sketchpadfür den Fixationspunkt (nennen wir es fixation_dot), das nach 0 ms angezeigt wird - Ein
sketchpadfür die Stimulusanzeige (nennen wir es objects), das nach 1000 ms angezeigt wird - Ein
samplerfür den Ton (nennen wir es spoken_sentence), das nach 2000 ms angezeigt wird
Die Struktur deines Experiments sollte jetzt aussehen wie in Figure 6.
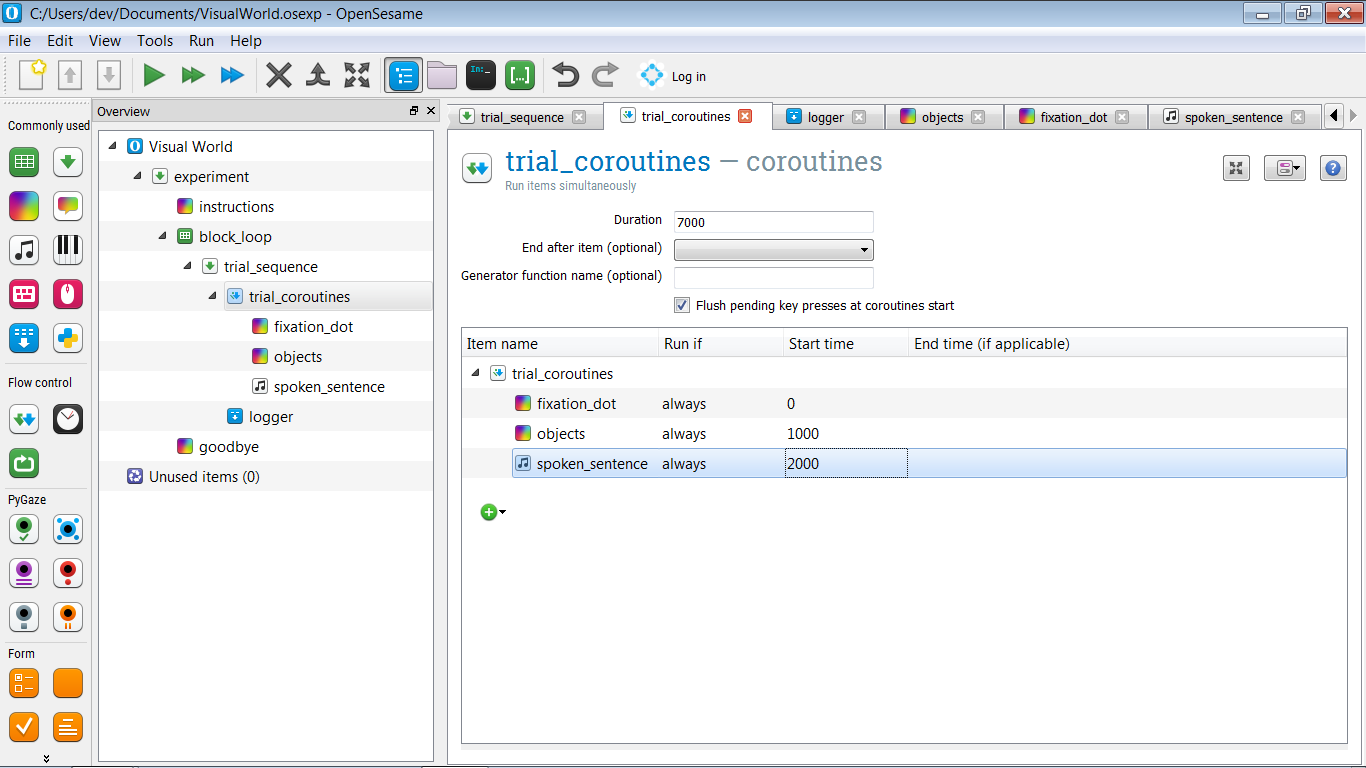
Figure 6. Die Struktur des Experiments nach der Definition der Versuchssequenz.
Schritt 7: Definiere die visuellen Stimuli
fixation_dot
Der fixation_dot ist leicht definiert: Zeichne einfach einen zentralen Fixationspunkt darauf.
Beachte, dass du nicht die Dauer des sketchpad angeben musst, wie du es normalerweise tun müsstest; dies liegt daran, dass das Element Teil von trial_coroutines ist und die Zeit durch die dort angegebenen Start- und Endzeit bestimmt wird.
objects
Um die objects zu definieren, erstelle zuerst eine Prototyp-Anzeige, ein Beispiel dafür, wie eine Anzeige bei einem bestimmten Versuch aussehen könnte. Zeichne dabei einen zentralen Fixationspunkt und zeichne in jedem der vier Quadranten ein willkürliches Bild, wie in Figure 7 dargestellt.
Gib den vier Objekten auch einen Namen: pic1, pic2, pic3 und pic4. Wir werden diese Namen in den Extra-Aufgaben verwenden, um eine Regions-of-Interest-(ROI)-Analyse durchzuführen.
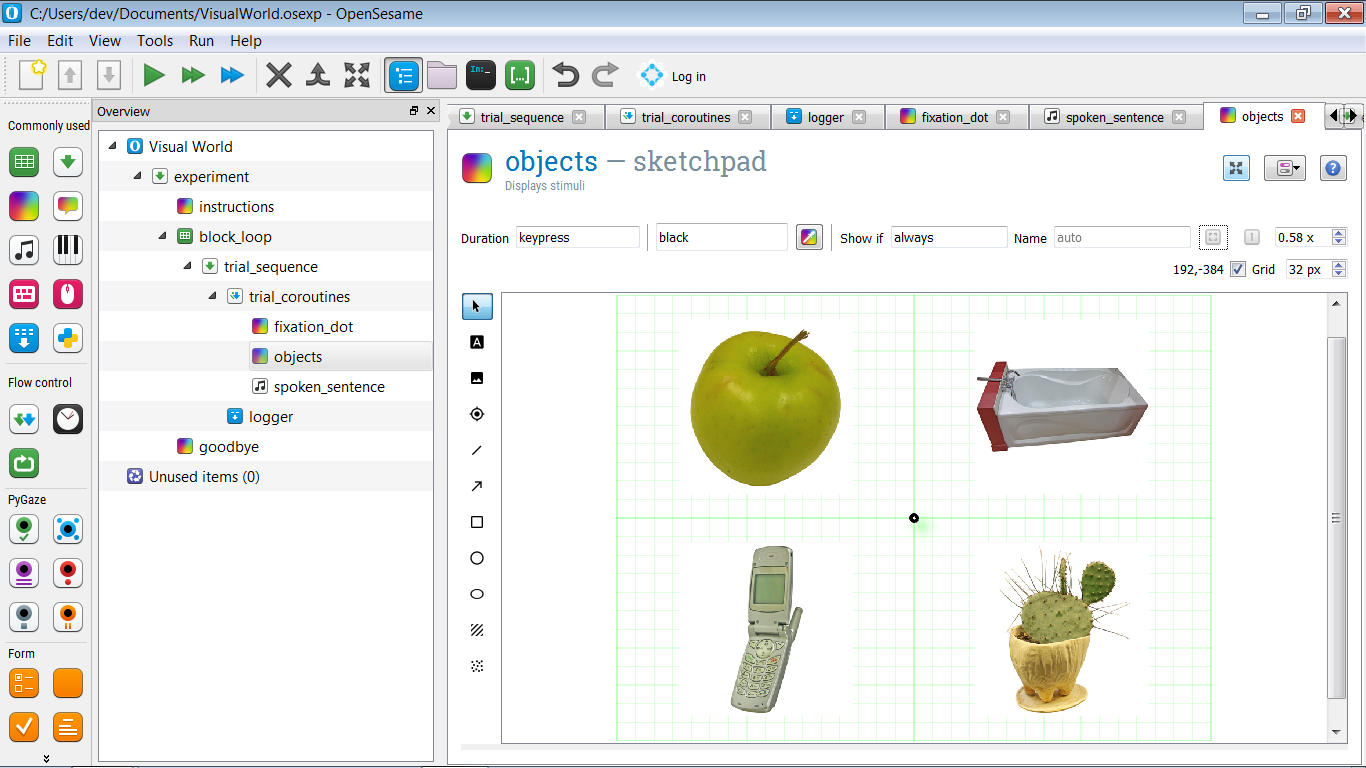
Figure 7. Eine Prototyp-Anzeige mit einem willkürlichen Objekt in jedem der vier Quadranten.
Natürlich wollen wir nicht immer wieder die gleichen Objekte zeigen. Vielmehr möchten wir, dass die pic[x]-Variablen angeben, welche Objekte angezeigt werden, und die pos[x]-Variablen angeben, wo diese Objekte angezeigt werden. Fangen wir mit dem ersten Objekt an: dem Objekt oben links, bei meinem Beispiel ist es ein Apfel.
Öffne das Skript und suche die Zeile, die dem ersten Objekt entspricht. In meinem Beispiel ist dies die folgende Zeile:
draw image center=1 file="apple.jpg" scale=1 show_if=always x=-256 y=-192 z_index=0
Ändere nun file="apple.jpg" in file=[pic1]. Dies stellt sicher, dass das Zielbild, wie es in der pic1-Variablen angegeben ist, gezeigt wird, anstatt immer denselben Apfel.
Wie können wir also pos1, das Werte wie 'topleft', 'bottomright' usw. hat, verwenden, um die X- und Y-Koordinaten des Bildes festzulegen? Um dies zu tun, nutzen wir die Tatsache, dass wir Python-Ausdrücke in OpenSesame-Skript einbetten können, indem wir die [=python_expression]-Notation verwenden:
- Ändere
x=-256inx="[=-256 if 'left' in var.pos1 else 256]" - Ändere
y=-192iny="[=-192 if 'top' in var.pos1 else 192]"
Und mache dasselbe für die anderen Bilder, bis das Skript so aussieht:
zeichne fixdot color=schwarz show_if=immer style=standard x=0 y=0 z_index=0
zeichne bild center=1 file="[bild1]" scale=1 show_if=immer x="[=-256 if 'links' in var.pos1 else 256]" y="[=-192 if 'oben' in var.pos1 else 192]" z_index=0
zeichne bild center=1 file="[bild2]" scale=1 show_if=immer x="[=-256 if 'links' in var.pos2 else 256]" y="[=-192 if 'oben' in var.pos2 else 192]" z_index=0
zeichne bild center=1 file="[bild3]" scale=1 show_if=immer x="[=-256 if 'links' in var.pos3 else 256]" y="[=-192 if 'oben' in var.pos3 else 192]" z_index=0
zeichne bild center=1 file="[bild4]" scale=1 show_if=immer x="[=-256 if 'links' in var.pos4 else 256]" y="[=-192 if 'oben' in var.pos4 else 192]" z_index=0
Probieren Sie es selbst aus: der if-Ausdruck
Wenn Sie mit dem Python if Ausdruck, der sich etwas von der herkömmlichen if Anweisung unterscheidet, nicht vertraut sind, öffnen Sie das Debug-Fenster und geben Sie die folgende Zeile ein:
print('Dies wird angezeigt, wenn True' if True sonst 'Dies wird angezeigt, wenn False')
Was sehen Sie? Ändern Sie nun if True else in if False else und führen Sie die Zeile erneut aus. Was sehen Sie jetzt? Verstehen Sie die Logik?
Schritt 8: Definieren Sie den Ton
Das Definieren des Tons ist einfach: Öffnen Sie einfach das Element gesprochener_Satz und geben Sie '[sound]' in das Feld 'Tondatei' ein, um anzugeben, dass die Variable sound die Tondatei angibt.
Schritt 9: Grundlegendes Eye-Tracking hinzufügen
Eye-Tracking wird mit den PyGaze Plug-ins durchgeführt, die standardmäßig in OpenSesame installiert sind. Das allgemeine Verfahren ist wie folgt:
- Zu Beginn des Experiments wird der Eye-Tracker mit dem Element
pygaze_initinitialisiert und kalibriert. Hier geben Sie auch an, welchen Eye-Tracker Sie verwenden möchten. Währenddessen ist es praktisch, den Advanced Dummy Eye-Tracker auszuwählen, mit dem Sie Augenbewegungen mit der Maus simulieren können. - Vor jedem Versuch wird ein Driftkorrektur-Verfahren mit dem
pygaze_drift_correct-Element durchgeführt. Während der Driftkorrektur wird ein einzelner Punkt auf dem Bildschirm angezeigt, auf den der Teilnehmer schaut. Dadurch kann der Eye-Tracker sehen, wie groß der Driftfehler in der Augenpositions-Messung ist. Wie dieser Fehler behandelt wird, hängt von Ihrem Eye-Tracker und den Einstellungen ab: - Der Driftfehler wird entweder für eine Einzelpunkt-Rekalibrierung verwendet
- Oder es wird einfach überprüft, ob der Driftfehler einen bestimmten maximalen Fehler nicht überschreitet und die Möglichkeit zur Rekalibrierung besteht, wenn der maximale Fehler überschritten wird.
- Als Nächstes wird dem Eye-Tracker vor jedem Versuch, mit dem Element
pygaze_start_recording, gesagt, dass er Daten erfassen soll. Sie können eine Statusmeldung angeben, um den Start jedes Versuchs anzuzeigen. Es ist praktisch, in dieser Statusmeldung eine Versuchsnummer (z. B. 'start_trial [count_trial_sequence]') aufzunehmen. - Am Ende jedes Versuchs werden die Daten mit dem
pygaze_log-Element an die Eye-Tracker-Protokolldatei gesendet. Es ist praktisch, die Option "Automatisch alle Variablen erkennen und protokollieren" zu aktivieren. - Schließlich wird am Ende jedes Versuchs dem Eye-Tracker mit dem Element
pygaze_stop_recordinggesagt, dass die Aufzeichnung beendet ist.
Die Struktur Ihres Experiments sollte nun wie in Figure 8 aussehen.
![]()
Figure 8. Die Struktur des Experiments nach Hinzufügen von PyGaze-Elementen für das Eye-Tracking.
Schritt 10: Anweisungen und Abschiedsbildschirm definieren
Wir haben jetzt ein funktionierendes Experiment! Aber wir haben den Anweisungs- und Auf-Wiedersehen-Elementen noch keinen Inhalt hinzugefügt. Bevor Sie also das Experiment ausführen, öffnen Sie diese Elemente und fügen Sie etwas Text hinzu.
Schritt 11: Führen Sie das Experiment aus!
Herzlichen Glückwunsch - Sie haben ein visuelles Welt-Paradigma implementiert! Jetzt ist es an der Zeit, Ihrem Experiment einen kurzen Testlauf zu geben, indem Sie auf die orangefarbene Schaltfläche "Play" klicken (Tastenkombination: Strg+Umschalt+W).
Zusatzaufgaben
Extra 1: Definieren Sie die semantische Übereinstimmungsbedingung
Bisher haben wir nur die Bedingung "Vollständige Übereinstimmung" implementiert, bei der das Zielobjekt (z.B. "Apfel") ausdrücklich im gesprochenen Satz (z.B. "beim Frühstück aß das Mädchen einen Apfel") erwähnt wird.
Implementiere nun auch die Bedingung "Semantische Übereinstimmung", bei der jedes Ziel (z.B. "Apfel") mit einem semantisch verwandten gesprochenen Satz (z.B. "beim Frühstück aß das Mädchen eine Banane") kombiniert wird. Die Reize wurden so erstellt, dass es für jedes Zielobjekt einen semantisch verwandten gesprochenen Satz gibt.
In jeder anderen Hinsicht sollte die Bedingung "Semantische Übereinstimmung" identisch mit der Bedingung "Vollständige Übereinstimmung" sein.
Und vergiss nicht, eine Variable anzulegen, die die Bedingung angibt!
Extra 2: Verwende Python-Konstanten, um Koordinaten zu definieren
Momentan sind die Koordinaten der Objekte im objects-Skript fest verdrahtet, in dem Sinne, dass die Koordinaten direkt in das Skript eingegeben wurden:
x="[=-256 if 'left' in var.pos1 else 256]"
Es ist eleganter, die Koordinaten (XLEFT, XRIGHT, YTOP und YBOTTOM) als Konstanten in einem inline_script am Anfang des Experiments zu definieren und dann in dem objects-Skript auf diese Konstanten zu verweisen.
Konstanten in Python
In der Informatik ist eine Konstante eine Variable mit einem Wert, den man nicht ändern kann. In Python kann man Variablen immer ändern, daher gibt es streng genommen keine echten Konstanten in der Sprache. Wenn du jedoch eine Variable hast, die du so behandelst, als wäre sie eine Konstante (d.h. du definierst sie einmal und änderst ihren Wert nie), dann kennzeichnest du dies normalerweise durch Schreiben des Variablennamens in ALL_CAPS.
Solche Namenskonventionen werden in den PEP-8-Stilrichtlinien von Python beschrieben:
Extra 3: Analysiere Augenpositionen online (herausfordernd!)
In trial_coroutines kannst du den Namen einer Generatorfunktion angeben (siehe unten für eine Erklärung von Generatoren). Gib hier den Namen roi_analysis ein und erstelle auch ein inline_script am Anfang des Experiments, in dem du diese Funktion definierst.
Hier ist eine teilweise implementierte roi_analysis() Funktion. Kannst du die TODO-Liste vervollständigen?
def roi_analysis():
# sample_nr wird verwendet, um für jede
# 500 ms Probe einen anderen Variablennamen zu erstellen
sample_nr = 0
# Dieses erste Yield zeigt an, dass der Generator mit der Vorbereitung fertig ist
yield
# Hole die Leinwand des objects sketchpad. Wir müssen dies nach
# dem Yield-Befehl tun, der das Ende der Vorbereitung signalisiert, weil das wir
# sicher sind, dass das Leinwand-Objekt erstellt wurde (was auch geschieht)
# während der Vorbereitung.
canvas = items['objects'].canvas
while True:
# Wir möchten nur alle 500 ms eine Gaze-Probe analysieren. Das tun wir, damit wir
# nicht zu viele Spalten in der Logdatei erhalten. Wenn es noch nicht Zeit ist, eine Gaze-Probe zu
# analysieren, gib einfach nach und mach weiter.
if not clock.once_in_a_while(ms=500):
yield # damit andere Items in den coroutines laufen können
continue
#
# TODO:
#
# - Hole eine Augenpositions-Koordinate vom Eye-Tracker
# (Hinweis: Verwende eyetracker.sample())
# - Überprüfe, welche Sketchpad-Elemente bei dieser Koordinate vorhanden sind (falls vorhanden)
# (Hinweis: Verwende canvas.elements_at())
# - Wenn pic1 (das Zielobjekt) unter diesen Elementen ist, setze var.on_target_[sample_nr] auf 1, sonst auf 0
# (Hinweis: verwende var.set())
Siehe auch:
Generatorfunktionen in Python
In Python ist eine Generator-Funktion eine Funktion mit einer yield-Anweisung. Eine yield-Anweisung ist ähnlich wie eine return-Anweisung, da sie eine Funktion stoppt. Im Gegensatz zu return, die eine Funktion dauerhaft stoppt, setzt yield eine Funktion nur aus – und die Funktion kann später von der yield-Stelle an fortgesetzt werden.
Lade das Experiment herunter
Das vollständige Experiment gibt es hier zum Download:
Literaturangaben
Brodeur, M. B., Dionne-Dostie, E., Montreuil, T., Lepage, M. & Op de Beeck, H. P. (2010). Die Bank der standardisierten Reize (BOSS), ein neuer Satz von 480 normativen Fotos von Objekten, die als visuelle Reize in der kognitiven Forschung verwendet werden. PloS ONE, 5(5), e10773. doi:10.1371/journal.pone.0010773
Cooper, R. M. (1974). Die Steuerung der Augenfixation durch die Bedeutung gesprochener Sprache: Eine neue Methodik zur Echtzeit-Untersuchung von Sprachwahrnehmung, Gedächtnis und Sprachverarbeitung. Kognitive Psychologie, 6(1), 84–107. doi:10.1016/0010-0285(74)90005-X
Dalmaijer, E., Mathôt, S. & Van der Stigchel, S. (2014). PyGaze: Eine Open-Source-, plattformübergreifende Toolbox für den minimalen Programmieraufwand von Eyetracking-Experimenten. Verhaltensforschungsmethoden, 46(4), 913–921. doi:10.3758/s13428-013-0422-2
Huettig, F., Rommers, J. & Meyer, A. S. (2011). Verwendung des visuellen Welt-Paradigmas zur Erforschung von Sprachverarbeitung: Eine Überprüfung und kritische Bewertung. Acta Psychologica, 137(2), 151–171. doi:10.1016/j.actpsy.2010.11.003
Mathôt, S., Schreij, D. & Theeuwes, J. (2012). OpenSesame: Ein Open-Source-, grafischer Experiment-Builder für die Sozialwissenschaften. Verhaltensforschungsmethoden, 44(2), 314–324. doi:10.3758/s13428-011-0168-7