


Registro y lectura de archivos de datos
¡Siempre verifica tres veces si tus datos se han registrado correctamente antes de ejecutar tu experimento!
Usando el elemento logger
OpenSesame no registrará tus datos automáticamente. En lugar de eso, necesitas insertar un elemento logger, típicamente al final de tu secuencia de ensayos.
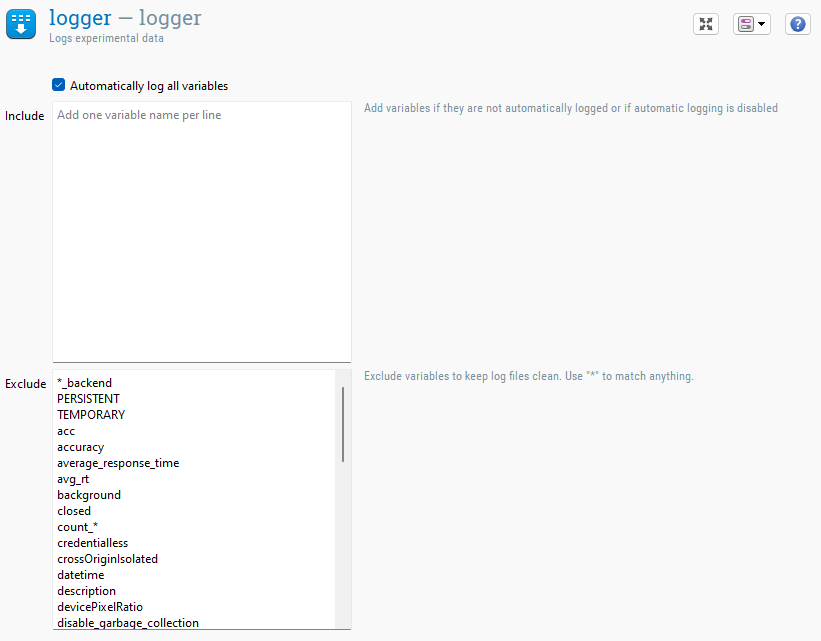
Figure 1. El elemento logger.
La forma más sencilla de usar el logger es dejando habilitada la opción 'Registrar automáticamente todas las variables'. De esta manera, todas las variables que OpenSesame conoce se escriben en el archivo de registro, excepto aquellas que están explícitamente excluidas (ver más abajo).
Puedes incluir explícitamente cuáles variables quieres registrar. La razón principal para hacer esto es cuando encuentras que algunas variables faltan (porque OpenSesame no las detectó automáticamente), o si has deshabilitado la opción 'Registrar automáticamente todas las variables'.
También puedes excluir explícitamente ciertas variables del archivo de registro. La razón principal para hacerlo es mantener limpios los archivos de registro excluyendo variables que generalmente no son útiles.
En general, deberías crear solo un elemento logger, y reutilizar ese logger en diferentes ubicaciones de tu experimento si es necesario (es decir, usar copias vinculadas del mismo elemento logger). Si creas múltiples loggers (en lugar de usar un único logger varias veces), todos ellos escribirán en el mismo archivo de registro, ¡y el resultado será un desastre!
Usando el script inline de Python
Puedes escribir en el archivo de registro utilizando el objeto log:
log.write('¡Esto se escribirá en el archivo de registro!')
Para más información, consulta:
Generalmente no deberías escribir directamente en el archivo de registro y usar un elemento logger al mismo tiempo; hacerlo resultará en archivos de registro desordenados.
Formato de los archivos de datos
Si has usado el elemento logger estándar, los archivos de datos están en el siguiente formato (simplemente csv estándar):
- texto plano
- separado por comas
- entrecomillado doble (comillas dobles literales se escapan con barras invertidas)
- finales de línea al estilo Unix
- codificado en UTF-8
- nombres de las columnas en la primera fila
¿Qué variables se registran?
Por defecto, se registran las variables que están definidas en la interfaz de usuario, como las columnas en una tabla de loop o las variables de respuesta.
Por defecto, se registran las variables que se definen en un inline_script o inline_javascript si son números (int y float), cadenas (str y bytes) y valores None. Esto se hace para evitar que los archivos de registro se vuelvan irrazonablemente grandes debido al registro de listas largas y otros valores grandes. (A partir de OpenSesame 4.0, ya no es necesario usar el objeto var (Python) o vars (JavaScript)).
Si quieres registrar explícitamente una variable que no se registra por defecto, puedes usar el campo 'Include' en el elemento logger.
Leyendo y procesando archivos de datos
En Python con pandas o DataMatrix
En Python, puedes usar pandas para leer archivos csv.
import pandas
df = pandas.read_csv('subject-1.csv')
print(df)
O DataMatrix:
from datamatrix import io
dm = io.readtxt('subject-1.csv')
print(dm)
En R
En R, simplemente puedes usar la función read.csv() para leer un solo archivo de datos.
df = read.csv('subject-1.csv', encoding = 'UTF-8')
head(df)
Además, puedes usar la función read_opensesame() del paquete readbulk para leer y unir fácilmente múltiples archivos de datos en un gran data frame. El paquete está disponible en CRAN y se puede instalar a través de install.packages('readbulk').
# Leer y unir todos los archivos de datos almacenados en la carpeta 'raw_data'
library(readbulk)
df = read_opensesame('raw_data')
En JASP
JASP, un paquete de estadísticas de código abierto, abre archivos csv directamente.
En LibreOffice Calc
Si abres un archivo csv en LibreOffice Calc, debes indicar el formato exacto de los datos, como se muestra en Figure 2. (La configuración predeterminada suele ser la correcta.)
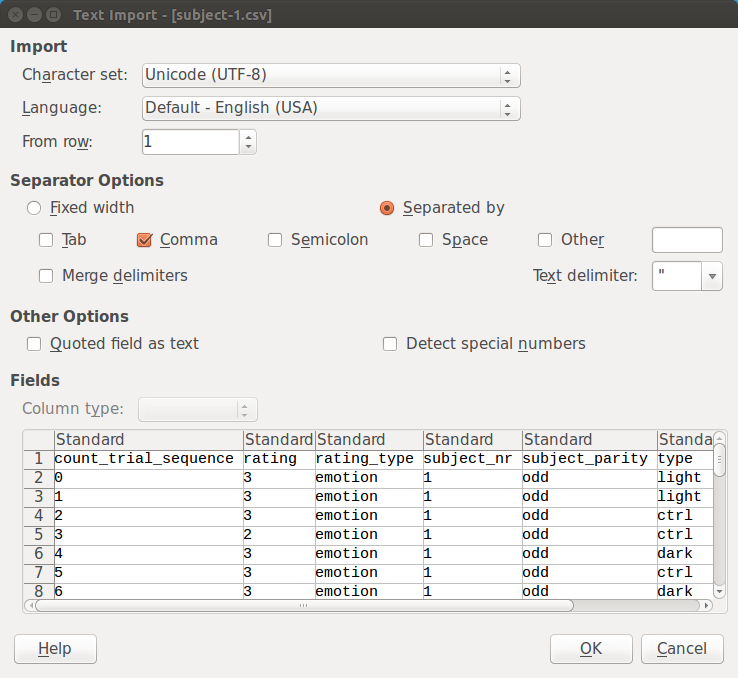
Figure 2.
En Microsoft Excel
En Microsoft Excel, necesitas usar el Asistente para importación de texto.
Fusionar varios archivos de datos en un solo archivo grande
Para algunos propósitos, como utilizar tablas dinámicas, puede ser conveniente fusionar todos los archivos de datos en un solo archivo grande. Con Python DataMatrix, puedes hacer esto con el siguiente script:
import os
from datamatrix import DataMatrix, io, operations as ops
# Cambia esto por la carpeta que contiene los archivos .csv
SRC_FOLDER = 'student_data'
# Cambia esto por una lista de nombres de columnas que quieras mantener
COLUMNS_TO_KEEP = [
'RT_search',
'load',
'memory_resp'
]
dm = DataMatrix()
for basename in os.listdir(SRC_FOLDER):
path = os.path.join(SRC_FOLDER, basename)
print('Leyendo {}'.format(path))
dm <<= ops.keep_only(io.readtxt(path), *COLUMNS_TO_KEEP)
io.writetxt(dm, 'merged-data.csv')
Registro de datos en OSWeb
Cuando ejecutas un experimento en un navegador con OSWeb, el registro de datos funciona de manera diferente a cuando lo ejecutas en el escritorio.
Específicamente, cuando lanzas un experimento de OSWeb directamente desde OpenSesame, el archivo de registro se descarga al final del experimento. Este archivo de registro está en formato .json. Cuando lanzas un experimento de OSWeb desde JATOS, no hay un archivo de registro como tal, sino que todos los datos se envían a JATOS desde donde se pueden descargar.
Ver también: