






Logging and reading data files
Always triple check whether your data has been logged correctly before running your experiment!
Using the logger item
OpenSesame will not log your data automatically. Instead, you need to insert a logger item, typically at the end of your trial sequence.
Figure 1. The logger item.
The simplest way to use the logger is by leaving the 'Log all variables (recommended)' enabled. That way, all variables that OpenSesame knows about are written the log file.
If you find that some variables are missing, you can explicitly add the name of a custom variable, or drag a variable from the variable inspector into the logger table.
If you prefer to log only certain variables, you can disable the 'Log all variables' option, and indicate explicitly which variables you want to log.
In general, you should create only one logger item, and reuse that logger at different locations in your experiment if necessary (i.e. use linked copies of the same logger item). If you create multiple loggers (rather than using a single logger multiple times), they will all write to the same log file, and the result will be a mess!
Using Python inline script
You can write to the log file using the log object:
log.write('This will be written to the log file!')
For more information, see:
You should generally not write to the log file directly and use a logger item at the same time; doing so will result in messy log files.
Format of the data files
If you have used the standard logger item, data files are in the following format format (simply standard csv):
- plain-text
- comma-separated
- double-quoted (literal double-quotes are escaped with backward slashes)
- unix-style line endings
- UTF-8 encoded
- column names on the first row
Reading and processing data files
In Python with pandas or DataMatrix
In Python, you can use pandas to read csv files.
import pandas
df = pandas.read_csv('subject-1.csv')
print(df)
Or DataMatrix:
from datamatrix import io
dm = io.readtxt('subject-1.csv')
print(dm)
In R
In R, you can simply use the read.csv() function to read a single data file.
df = read.csv('subject-1.csv', encoding = 'UTF-8')
head(df)
In addition, you can use the read_opensesame() function from the readbulk package to easily read and merge multiple data files into one large data frame. The package is available on CRAN and can be installed via install.packages('readbulk').
# Read and merge all data files stored in the folder 'raw_data'
library(readbulk)
df = read_opensesame('raw_data')
In JASP
JASP, an open-source statistics package, opens csv files straight away.
In LibreOffice Calc
If you open a csv file in LibreOffice Calc, you have to indicate the exact data format, as indicated in Figure 2. (The default settings are often correct.)
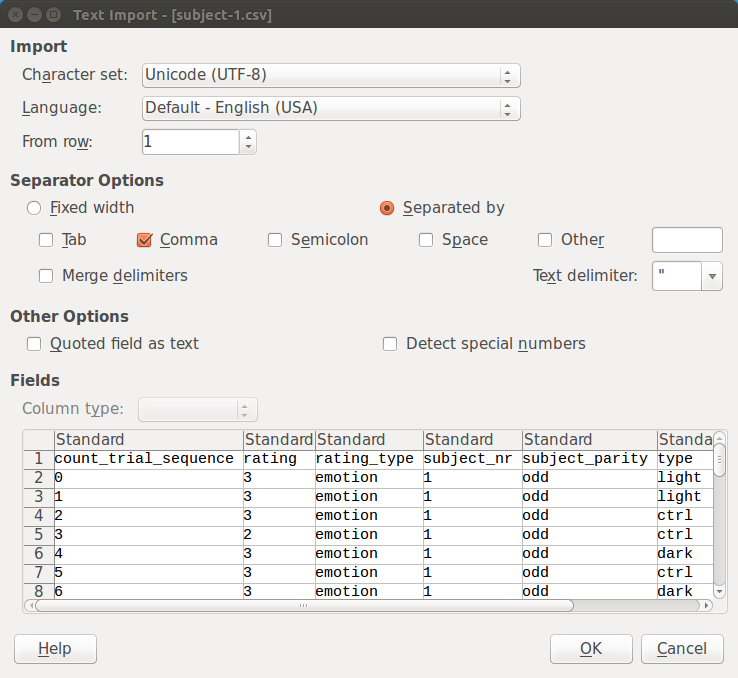
Figure 2.
In Microsoft Excel
In Microsoft Excel, you need to use the Text Import Wizard.
Merging multiple data files into one large file
For some purposes, such as using pivot tables, it may be convenient to merge all data files into one large file. With Python DataMatrix, you can do this with the following script:
import os
from datamatrix import DataMatrix, io, operations as ops
# Change this to the folder that contains the .csv files
SRC_FOLDER = 'student_data'
# Change this to a list of column names that you want to keep
COLUMNS_TO_KEEP = [
'RT_search',
'load',
'memory_resp'
]
dm = DataMatrix()
for basename in os.listdir(SRC_FOLDER):
path = os.path.join(SRC_FOLDER, basename)
print('Reading {}'.format(path))
dm <<= ops.keep_only(io.readtxt(path), *COLUMNS_TO_KEEP)
io.writetxt(dm, 'merged-data.csv')